
티스토리 뷰
INTRO
1. 후진 제거법(Backward Elimination)
3. 단계별 방법(Stepwise Method)
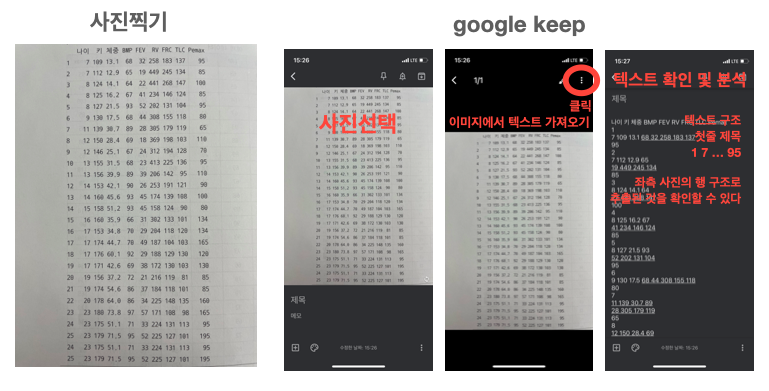
# 참고 : 텍스트북 사진 찍고 텍스트 추출하기
구글킵(google keep) app 사용
- 추출을 원하는 텍스트를 포함하도록 사진을 찍는다.
- google keep을 다운 받아 app을 시전한다.
- 사진을 선택하고 사진 전체를 터치하면 우상단에 메뉴에서 "이미지에서 텍스트 가져오기"를 클릭
- "이미지에서 텍스트 가져오기"는 동기화 시간에 따라 짧은 시간이 필요하다.
- 추출된 텍스트를 확인하여 구조를 분석하면 쉽게 텍스트(데이터)를 구조화 할 수 있다.
3. 단계별 방법
전진 선택법에 의해 변수를 추가하면서 그로인해 기인된 기존 변수의 중요도가 약화되면 해당 변수를 제거하는 등 단계별로 추가 또는 제거의 여부를 검토해 더 이상 없을 때 중단하는 방법
dataset
google keep으로 추출한 텍스트북 bio_data.csv
후진 제거법(Backward Elimination)
test_stepwise_variable_selection.R
rm(list=ls())
setwd = "~/Rcoding"
Bio = read.csv("~/Rcoding/bio_data.csv")
Bio
## Backward Elimination
step_backward_model = step(lm(Pemax ~ 나이+키+체중+BMP+RV+FRC+TLC, data=Bio), direction="backward")
step_backward_model출력결과 : step_backward_model
> source("~/Rcoding/test_stepwise_variable_selection.R", echo=TRUE)
> rm(list=ls())
> setwd = "~/Rcoding"
> Bio = read.csv("~/Rcoding/bio_data.csv")
> Bio
번호 나이 키 체중 BMP FEV RV FRC TLC Pemax
1 1 7 109 13.1 68 32 258 183 137 95
2 2 7 112 12.9 65 19 449 245 134 85
3 3 8 124 14.1 64 22 441 268 147 100
4 4 8 125 16.2 67 41 234 146 124 85
5 5 8 127 21.5 93 52 202 131 104 95
6 6 9 130 17.5 68 44 308 155 118 80
7 7 11 139 30.7 89 28 305 179 119 65
8 8 12 150 28.4 69 18 369 198 103 110
9 9 12 146 25.1 67 24 312 194 128 70
10 10 13 155 31.5 68 23 413 225 136 95
11 11 13 156 39.9 89 39 206 142 95 110
12 12 14 153 42.1 90 26 253 191 121 90
13 13 14 160 45.6 93 45 174 139 108 100
14 14 15 158 51.2 93 45 158 124 90 80
15 15 16 160 35.9 66 31 302 133 101 134
16 16 17 153 34.8 70 29 204 118 120 134
17 17 17 174 44.7 70 49 187 104 103 165
18 18 17 176 60.1 92 29 188 129 130 120
19 19 17 171 42.6 69 38 172 130 103 130
20 20 19 156 37.2 72 21 216 119 119 85
21 21 19 174 54.6 86 37 184 118 101 85
22 22 20 178 64.0 86 34 225 148 135 160
23 23 23 180 73.8 97 57 171 108 98 165
24 24 23 175 51.1 71 33 224 131 113 95
25 25 23 179 71.5 95 52 225 127 101 195
> ## Backward Elimination
> step_backward_model = step(lm(Pemax ~ 나이+키+체중+BMP+RV+FRC+TLC, data=Bio), direction="backward")
Start: AIC=169.5
Pemax ~ 나이 + 키 + 체중 + BMP + RV + FRC + TLC
Df Sum of Sq RSS AIC
- TLC 1 12.2 11612 167.52
- RV 1 651.0 12251 168.86
- 키 1 685.9 12286 168.93
- FRC 1 863.4 12464 169.29
<none> 11600 169.50
- 나이 1 1058.7 12659 169.68
- BMP 1 2457.0 14057 172.30
- 체중 1 4340.9 15941 175.44
Step: AIC=167.52
Pemax ~ 나이 + 키 + 체중 + BMP + RV + FRC
Df Sum of Sq RSS AIC
- 키 1 697.8 12310 166.98
- RV 1 756.6 12369 167.10
<none> 11612 167.52
- 나이 1 1074.8 12687 167.74
- FRC 1 1257.0 12870 168.09
- BMP 1 2643.2 14256 170.65
- 체중 1 4431.4 16044 173.60
Step: AIC=166.98
Pemax ~ 나이 + 체중 + BMP + RV + FRC
Df Sum of Sq RSS AIC
- RV 1 759.2 13070 166.48
<none> 12310 166.98
- FRC 1 1090.7 13401 167.10
- 나이 1 1263.1 13573 167.43
- BMP 1 1984.6 14295 168.72
- 체중 1 3967.1 16277 171.97
Step: AIC=166.48
Pemax ~ 나이 + 체중 + BMP + FRC
Df Sum of Sq RSS AIC
- FRC 1 339.8 13409 165.12
- 나이 1 976.4 14046 166.28
<none> 13070 166.48
- BMP 1 2716.5 15786 169.20
- 체중 1 3632.7 16702 170.61
Step: AIC=165.12
Pemax ~ 나이 + 체중 + BMP
Df Sum of Sq RSS AIC
- 나이 1 681.3 14090 164.36
<none> 13409 165.12
- BMP 1 2379.7 15789 167.21
- 체중 1 3324.7 16734 168.66
Step: AIC=164.36
Pemax ~ 체중 + BMP
Df Sum of Sq RSS AIC
<none> 14090 164.36
- BMP 1 1914.9 16006 165.54
- 체중 1 11328.6 25419 177.11
> step_backward_model
Call:
lm(formula = Pemax ~ 체중 + BMP, data = Bio)
Coefficients:
(Intercept) 체중 BMP
124.830 1.640 -1.005
전진 선택법(Forward Selection)
test_stepwise_variable_selection.R
...
## Forward Selection
step_forward_model = step(lm(Pemax ~ 1,Bio), scope=list(lower=~1,upper=~나이+키+체중+BMP+RV+FRC+TLC), direction="forward")
step_forward_model출력결과 : step_forward_model
...
> ## Forward Selection
> step_forward_model = step(lm(Pemax ~ 1,Bio), scope=list(lower=~1,upper=~나이+키+체중+BMP+RV+FRC+TLC), direction="forward")
Start: AIC=176.46
Pemax ~ 1
Df Sum of Sq RSS AIC
+ 체중 1 10827.2 16006 165.54
+ 나이 1 10098.5 16734 166.66
+ 키 1 9634.6 17198 167.34
+ FRC 1 4670.6 22162 173.68
+ RV 1 2671.8 24161 175.84
<none> 26833 176.46
+ TLC 1 1984.9 24848 176.54
+ BMP 1 1413.5 25419 177.11
Step: AIC=165.55
Pemax ~ 체중
Df Sum of Sq RSS AIC
+ BMP 1 1914.94 14090 164.36
<none> 16006 165.54
+ RV 1 274.55 15731 167.11
+ 나이 1 216.51 15789 167.21
+ 키 1 36.39 15969 167.49
+ FRC 1 27.34 15978 167.50
+ TLC 1 17.80 15988 167.52
Step: AIC=164.36
Pemax ~ 체중 + BMP
Df Sum of Sq RSS AIC
<none> 14090 164.36
+ 키 1 713.50 13377 165.06
+ 나이 1 681.28 13409 165.12
+ FRC 1 44.62 14046 166.28
+ TLC 1 27.48 14063 166.31
+ RV 1 18.84 14072 166.33
> step_forward_model
Call:
lm(formula = Pemax ~ 체중 + BMP, data = Bio)
Coefficients:
(Intercept) 체중 BMP
124.830 1.640 -1.005
단계별 방법(Stepwise Method)
test_stepwise_variable_selection.R
...
## stepwise mothod
step_stepwise_model = step(lm(Pemax ~ 1,Bio), scope=list(lower=~1,upper=~나이+키+체중+BMP+RV+FRC+TLC), direction="both")
step_stepwise_model출력결과 : step_stepwise_model
...
> ## stepwise mothod
> step_stepwise_model = step(lm(Pemax ~ 1,Bio), scope=list(lower=~1,upper=~나이+키+체중+BMP+RV+FRC+TLC), direction="both")
Start: AIC=176.46
Pemax ~ 1
Df Sum of Sq RSS AIC
+ 체중 1 10827.2 16006 165.54
+ 나이 1 10098.5 16734 166.66
+ 키 1 9634.6 17198 167.34
+ FRC 1 4670.6 22162 173.68
+ RV 1 2671.8 24161 175.84
<none> 26833 176.46
+ TLC 1 1984.9 24848 176.54
+ BMP 1 1413.5 25419 177.11
Step: AIC=165.55
Pemax ~ 체중
Df Sum of Sq RSS AIC
+ BMP 1 1914.9 14090 164.36
<none> 16006 165.54
+ RV 1 274.5 15731 167.11
+ 나이 1 216.5 15789 167.21
+ 키 1 36.4 15969 167.49
+ FRC 1 27.3 15978 167.50
+ TLC 1 17.8 15988 167.52
- 체중 1 10827.2 26833 176.46
Step: AIC=164.36
Pemax ~ 체중 + BMP
Df Sum of Sq RSS AIC
<none> 14090 164.36
+ 키 1 713.5 13377 165.06
+ 나이 1 681.3 13409 165.12
- BMP 1 1914.9 16006 165.54
+ FRC 1 44.6 14046 166.28
+ TLC 1 27.5 14063 166.31
+ RV 1 18.8 14072 166.33
- 체중 1 11328.6 25419 177.11
> step_stepwise_model
Call:
lm(formula = Pemax ~ 체중 + BMP, data = Bio)
Coefficients:
(Intercept) 체중 BMP
124.830 1.640 -1.005
Regression Analysis : step_forward_model
AIC(Akike Information Criterion)이 가장 작은 값을 갖는 모델을 최적 모델로 선택한다.
3가지 방법 모두 동일하며 AIC 선택 과정 설명은 여기를 클릭하여 참고한다.
# bio_data, 즉 의학데이터 용어
BMP : Bone Morphogenetic Protein, 골형성 단백질
FEV : Forced Expiratory Volume, 강제 호기량
RV : Residual Volume, 잔기량
FRC : Functional Residual Volume, 기능성 잔기량
TLC : Total Lung Capacity, 총폐용량
Pemax : MEP(Maximum Expiratory Pressure)를 다르게 부르는 말, 최대 호기압
>summary(step_stepwise_model)
Coefficients: Estimate Std. Error t value Pr(>|t|)
(Intercept) 124.8297 37.4786 3.331 0.003033 **
체중 1.6403 0.3900 4.206 0.000365 ***
BMP -1.0054 0.5814 -1.729 0.097797 .
--- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 25.31 on 22 degrees of freedom
Multiple R-squared: 0.4749, Adjusted R-squared: 0.4271
F-statistic: 9.947 on 2 and 22 DF, p-value: 0.0008374
F-statistic: 9.947, p-value: < 0.0008374로 유의수준 5% 하에서 추정된 회귀 모형이 통계적으로 유의함
(Intercept) p-value < 0.01, 체중 coef. p-value < 0.001, BMP coef. p-value < 0.1
Adjusted R-squared : 0.4271, 즉 추정된 회귀식이 데이터를 42.71% 설명함.
$ Pemax = 124.830 + 1.640*체중 - 1.005*BMP $
'R' 카테고리의 다른 글
| (macOS)[R] 다변량 분석 : 상관 분석(Correlation Analysis) - 2 (0) | 2022.04.16 |
|---|---|
| (macOS)[R] 다변량 분석 : 상관 분석(Correlation Analysis) - 1 (0) | 2022.04.16 |
| (macOS)[R] 기초 통계 분석 : 최적 회귀 방정식 선택(설명변수 선택) - 2 (0) | 2022.04.15 |
| (macOS)[R] 기초 통계 분석 : 최적 회귀 방정식 선택(설명변수 선택) - 1 (0) | 2022.04.14 |
| (macOS)[R] 기초 통계 분석 : 회귀 분석(Regression Analysis) - 4 (0) | 2022.04.13 |
- Total
- Today
- Yesterday
- ERP
- Python
- 코로나19
- SSH
- Pandas
- github
- 코로나
- analysis
- DS18B20
- Model
- Django
- COVID-19
- raspberrypi
- Templates
- MacOS
- 라즈베리파이
- template
- DAQ
- sublime text
- vscode
- Regression
- pyserial
- server
- git
- 자가격리
- CSV
- r
- arduino
- 확진
- Raspberry Pi
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |