
티스토리 뷰
INTRO
csv file 다루기
- File Handling : Create, Open/Close, Read, Write, list.append
xlsx file 다루기
- File Handling : Create, Open/Close, Read, Write, csv download & sheet handle
용어
CSV(Comma-Separated Values, Comma-Separated Variables)
몇 가지 필드를 쉼표(,)로 구분한 텍스트 데이터 및 텍스트 파일, 확장자는 .csv이며 MIME(Multipurpose Internet Mail Extensions, 전자 우편을 위한 인터넷 표준 포맷) 형식은 text/csv
스프레드시트나 데이터베이스 소프트웨어에서 많이 쓰였으나 세부적인 구현은 소프트웨어에 따라 다름
비슷한 포맷으로는 탭으로 구분하는 'tab-separated values'(TSV)나, 반각 스페이스로 구분하는 'space-separated values'(SSV) 등이 있으며, 이것들을 합쳐서 character-separated values (CSV), delimiter-separated values라고 부르는 경우가 많다.
출처 : ko.wikipedia.org/wiki/CSV_(파일_형식), ko.wikipedia.org/wiki/MIME
XLSX : 오피스 오픈 XML(Office Open XML, OOXML, 오픈XML)
XML을 기반으로 한 파일 포맷이다. 마이크로소프트가 추진하였으며, 이 문서 규격은 문서, 프레젠테이션, 스프레드시트를 포함
확장자는 .docx 또는 .docx(문서), .pptx(프레젠테이션), .xlsx(스프레드시트)로 통일
출처 : ko.wikipedia.org/wiki/오피스_오픈_XML
EXCEL
마이크로소프트 엑셀(Microsoft Excel)은 마이크로소프트 윈도우와 OS X에서 작동하는 마이크로소프트사에서 개발해 판매하는 스프레드시트 프로그램이다. 마이크로소프트 오피스의 일부이다. 회계 및 각종 데이터베이스 관리에 주로 사용된다.
출처 : ko.wikipedia.org/wiki/마이크로소프트_엑셀
1. CSV Handling
csv는 흔히 excel의 확장자 개념으로 알고 있지만 comma or tab으로 구분된 txt는 csv가 된다.
sublime text에서 빈창을 열어 다음 2개행(1행 tab 구분, 2행 comma 구분)을 입력하고 text_csv.txt와 text_csv.csv 두가지로 저장해 보자
1 2 3 4 5 6 7
1,2,3,4,5,6,7.csv 파일을 LibreOffice(or MS Office)에서 열면 다음과 같은 pop-up이 뜨는데 확인을 누르면 흔히 보던 csv가 열린다.
물론 .txt 파일을 LibreOffice로 열면 텍스트 문서로 열린다.

즉 tab, comma, semi-colon, 간격 등으로 구분된 txt 파일을 만들면 csv가 될 수 있다.
csv file을 만들고 data-type을 확인해보자. string과 list 형태로 읽는 방법을 소개한다.
python code : pyTest/test12.py
# -*- coding: utf-8 -*-
import os
#### path & text sample
base_path, sub_dirs, fnames = next(os.walk(os.getcwd()))
fnames = ['py_text1.txt','py_text2.txt','py_csv.csv']
text_r1 = '1 2 3 4 5 6 7'
text_r2 = '1,2,3,4,5,6,7'
text_list = [text_r1,text_r2]
#### try-except : make file without error
if os.path.isfile(os.path.join(base_path,fnames[0])):
try:
[os.remove(os.path.join(base_path,fname)) for fname in fnames]
except:
pass
#### create text, csv using write
with open(fnames[0],'w') as fw0:
fw0.write(text_r1)
fw0.write('\n')
fw0.write(text_r2)
with open(fnames[1],'w') as fw1:
for i in range(len(text_list)):
fw1.write(text_list[i])
fw1.write('\n')
with open(fnames[2],'w') as fw2:
fw2.write(text_r1)
fw2.write('\n')
fw2.write(text_r2)
#### text, csv read
with open(fnames[0], 'r') as fr0:
datas0 = fr0.read()
print("type is {}\ndata is 'string'\n{}\n".format(type(datas0),datas0))
with open(fnames[1], 'r') as fr1:
lines_readline = fr1.readlines()
print("type is {}\ndata is 'list'\n{}\n".format(type(lines_readline),lines_readline))
#### csv read using csv module
import csv
with open(fnames[2], 'r') as fr3:
lines_csv = csv.reader(fr3)
csv_outputs = []
for line_csv in lines_csv:
csv_outputs.append(line_csv)
print("type is {}\ndata is 'list set'\n{}\n".format(type(csv_outputs),csv_outputs))
---- SublimeText python Run test12.py ----
type is <class 'str'>
data is 'string'
1 2 3 4 5 6 7
1,2,3,4,5,6,7
type is <class 'list'>
data is 'list'
['1\t2\t3\t4\t5\t6\t7\n', '1,2,3,4,5,6,7\n']
type is <class 'list'>
data is 'list set'
[['1\t2\t3\t4\t5\t6\t7'], ['1', '2', '3', '4', '5', '6', '7']]
***Repl Closed***
공공데이터 포털(www.data.go.kr/index.do)에서 csv file 2개를 다운로드하여 xlsx 파일 sheet1, sheet2에 저장해보자.
file download : 내장hebf urllib.request의 urlretrieve를 이용
file encoding : 공공데이터 포털에서 받은 csv file은 EUC-KR로 encoding해야 UnicodeDecodeError 없이 정상 문자가 보임
openpyxl 설치 : 외장모듈(3rd party module)은 terminal에서 간단하게 설치할 수 있다.
$ python3 -m pip install --upgrade pip
$ python3 -m pip install update
$ python3 -m pip install openpyxl
ref. zsh aliases 만들어 활용하기
python3 -m pip .... zsh에서 명령어가 길어서 단축하여 별명처럼 사용
$ nano .zshrc
-------------------------------------------------------
GNU nano Editor : 마지막 줄에 내용 추가
...
# python aliases
alias pip='python3 -m pip'
-------------------------------------------------------
다음부터 terminal 명령어 입력시"python3 -m pip"를 "pip"로 단축하여 사용(작동 안하면 터미널 재가동)
python code : pyTest/test13.py
# -*- coding: utf-8 -*-
import os
from urllib.request import urlretrieve
import openpyxl
import csv
#### path & file sample
base_path, sub_dirs, fnames = next(os.walk(os.getcwd()))
base_dpath = './data'
urls = ['https://www.data.go.kr/cmm/cmm/fileDownload.do?atchFileId=FILE_000000002284060&fileDetailSn=1&insertDataPrcus=N',\
'https://www.data.go.kr/cmm/cmm/fileDownload.do?atchFileId=FILE_000000002278747&fileDetailSn=1&insertDataPrcus=N']
down_snames = ['file1.csv','file2.csv']
if not os.path.exists(base_dpath):
os.makedirs(os.path.join(base_path,base_dpath))
## dwonload using urlretrieve
[urlretrieve(urls[i], os.path.join(base_dpath,down_snames[i])) for i in range(len(urls))]
else:
pass
#### xlsx workboob handle using openpyxl
new_fname = 'py_wb_text.xlsx'
wb = openpyxl.Workbook()
sheet1 = wb.active
sheet1.title = down_snames[0].split('.')[0]
with open(os.path.join(base_dpath,down_snames[0]),'r',encoding='euc-kr') as f0:
lines_csv = csv.reader(f0)
for line_csv in lines_csv:
sheet1.append(line_csv)
wb.save(new_fname)
sheet2 = wb.create_sheet()
sheet2.title = down_snames[1].split('.')[0]
with open(os.path.join(base_dpath,down_snames[1]),'r',encoding='euc-kr') as f1:
lines_csv = csv.reader(f1)
for line_csv in lines_csv:
sheet2.append(line_csv)
wb.save(new_fname)
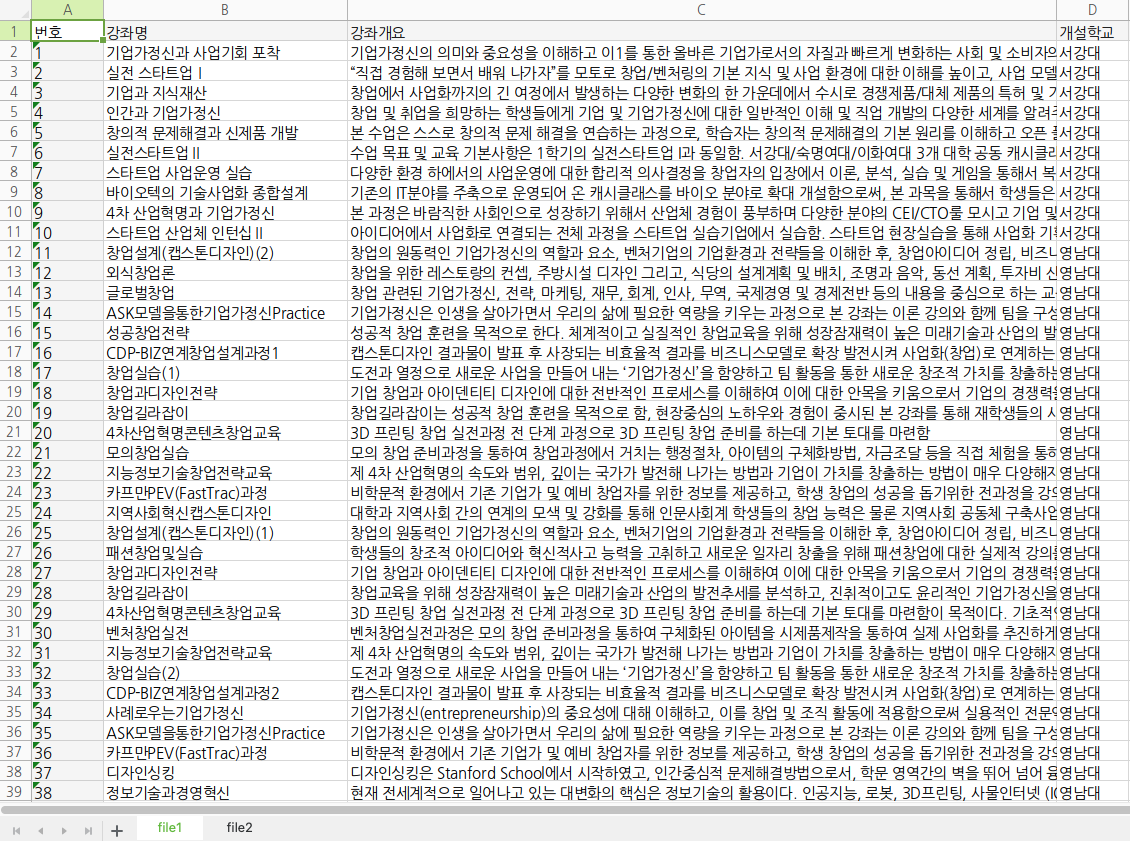
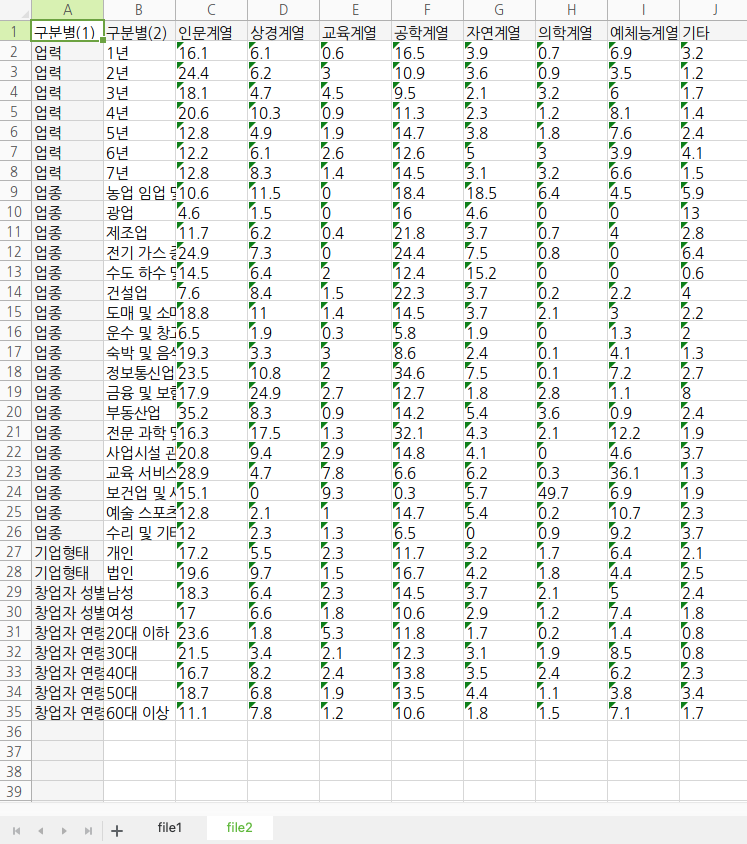
---- ./pyTest/data 디렉토리에 file1.csv와 file2.csv 확인 ----
---- ./pyTest/py_wb_text.xlsx 파일 열어서 확인 : 2개의 sheet와 내용이 들어있음. ----
'python > Lecture' 카테고리의 다른 글
| python 기초 #9 : Data Visualization(데이터 시각화) (0) | 2021.03.03 |
|---|---|
| python 기초 #8 : Database - SQLite (0) | 2021.03.03 |
| python 기초 #6 : File Handling - txt (0) | 2021.03.03 |
| python 기초 #5 : function(함수)/method(메서드)/module(모듈) (0) | 2021.02.26 |
| python 기초 #4 : Code Block(제어문 : 조건문/반복문) (0) | 2021.02.25 |
- Total
- Today
- Yesterday
- server
- MacOS
- 확진
- Templates
- COVID-19
- vscode
- github
- Raspberry Pi
- Python
- 코로나19
- Regression
- DAQ
- DS18B20
- analysis
- raspberrypi
- arduino
- Pandas
- pyserial
- 자가격리
- sublime text
- 라즈베리파이
- r
- Django
- Model
- SSH
- git
- CSV
- 코로나
- template
- ERP
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |